My prepared ppt for GANs review.
Classification of Problems and Related Paper:
First of all, read GANs tutorial from NIPS2016
1. Mode Collapse
The assumption of learning the full dataset well is not achieved, and only part of the dataset has been learned. The VAE can learned representation of the whole dataset, but not be very particular for each sample, while GANs can have sharp image, but encounter mode collapses more easily.
Unrolled GANs; (2017ICLR) ** Improves Techniques for Training GANs; (2016) *** On Distinguishability Criteria for Estimating Generative Models; (2014) ** Towards Principled Methods for training GANs; (2016) *** Mode Regularized GAN; (2016) ** Improved Training of Generative Adversarial Networks using Representative Features; (2018ICML) **
2. Non-convergence
We think it hard to achieve Nash equilibrium. Let me give a simple example for min-max two player game solved by simultaneous gradient descent methods.
On Distinguishability Criteria for Estimating Generative Models; (2014) ** Improves Techniques for Training GANs; (2016) *** f-GAN: Training Generative Sampler using Variational Divergence Minimization; (2016)*** Stabilizing Training of Generative Adversarial Networks through Regularization; (2017) ** The Numerics of GANS; (2017NIPS) ** Gradient descent GAN optimization is locally stable; (2017NIPS) ** Which Training Methods for GANs do actually Converge?; (2018ICML,very new) *** Improved Training of Generative Adversarial Networks using Representative Features; (2018ICML) **
3. Vanishing Gradient
When the final discriminator has been well trained, which means 

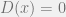

- Discriminator
bad behavior, the Generator and loss function cannot represent the data distribution
.
- Discriminator
Towards Principled Methods for training GANs; (2016) *** Wasserstein GAN; (2017) **** Improved Training of Wasserstein GANs; (2017NIPS) ***
4. Generalizability and Existence of Equilibrium
Generalization and Equilibrium in Generative Adversarial Nets (GANs); (2017) **
5. Evaluation methods for GANs
Improves Techniques for Training GANs; (2016) *** Pros and Cons of GAN Evaluation Measures; (2018) * Geometry Score: A Method For Comparing Generative Adversarial Networks

留下评论